AQA-Bench: An Interactive Benchmark for Evaluating LLMs’ Sequential Reasoning Ability in Algorithmic Environments
Abstract
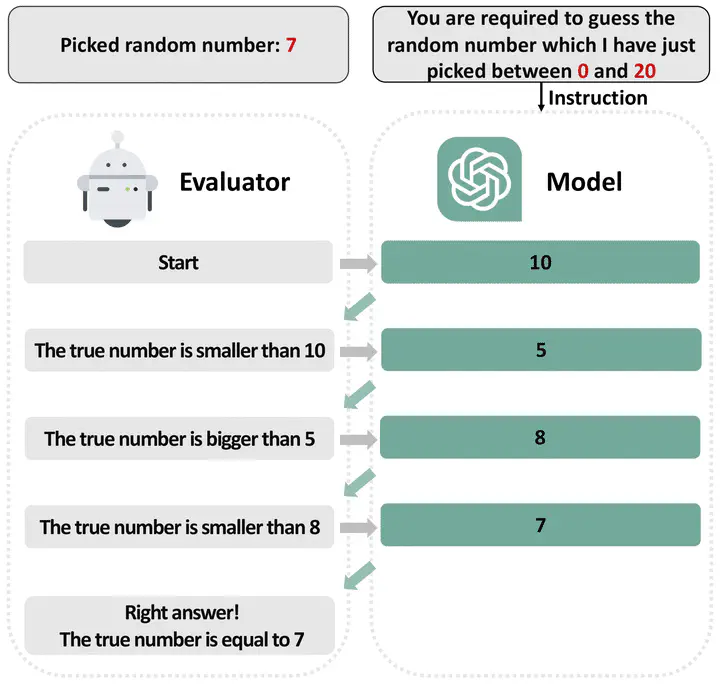
This paper introduces AQA-Bench, a novel benchmark to assess the sequential reasoning capabilities of large language models (LLMs) in algorithmic contexts, such as depth-first search (DFS). The key feature of our evaluation benchmark lies in its interactive evaluation protocol — for example, in DFS, the availability of each node’s connected edge is contingent upon the model’s traversal to that node, thereby necessitating the LLM’s ability to effectively remember visited nodes and strategize subsequent moves considering the possible environmental feedback in the future steps. We comprehensively build AQA-Bench with three different algorithms, namely binary search, depth-first search, and breadth-first search, and to evaluate the sequential reasoning ability of 14 different LLMs. Our investigations reveal several interesting findings: (1) Closed-source models like GPT-4 and Gemini generally show much stronger sequential reasoning ability, significantly outperforming open-source LLMs. (2) Naively providing in-context examples may inadvertently hurt few-shot performance in an interactive environment due to over-fitting to examples. (3) Instead of using optimal steps from another test case as the in-context example, a very limited number of predecessor steps in the current test case following the optimal policy can substantially boost small models’ performance. (4) Weak models’ under-performance is mainly due to the incapability to start well rather than maintain performance. (5) The scaling correlation between performance and model size is not always significant, sometimes even showcasing an inverse trend. We hope our study can catalyze future work on advancing the understanding and enhancement of LLMs’ capabilities in sequential reasoning.
Siwei Yang
Ph.D. in Computer Science
My research interests include distributed robotics, mobile computing and programmable matter.